Here’s something to consider. A person terrified about their own safety aspires to amass power and wealth. Why? Because they are terrified about their own safety. So they hoard, and the hoard grows without limit, because it exists to offset a fear of losing control or status.
And so they enter the AI market and tell everyone they are terrified about their own safety because of… AI.
Sure, sure, we believe it is AI that puts the executive in danger. We also believed it was the cans when Steve Martin, standing in front of the cans in 1979, yelled “He hates these cans! Stay away from the cans!”
Earlier this year, the AI industry was shaken when a 20-year-old anti-AI activist named Daniel Moreno-Gama, armed with a gun and a Molotov cocktail, unsuccessfully tried to firebomb the home of OpenAI CEO Sam Altman. No one was injured…
Anti-AI activist. Or anti-can activist?
One man, armed with one gun and one bottle of alcohol, shook the industry.
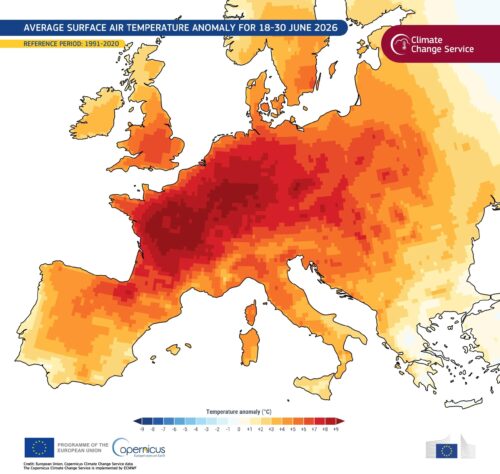
Heat that hit Europe exceptionally early and hard this year appears to have led to a spike in deaths, with well over 10,000 more people dying at the height of the heat wave than would normally have been expected…
Well, suddenly, unexpectedly, over 10,000 people dead? Yeah, so, is anyone stirred by that? Anyway back to the shaken AI industry, because someone could get hurt or even die.
Years ago, when I was working with Yahoo executives, I couldn’t help but notice that Marissa Mayer came in as CEO with constant body guards. Was there a threat? She didn’t get body guards for other staff, because it seemed to be a perception that the threat was attached to only top success. In fact, she built a daycare for her child, and hers alone, in the Yahoo campus, and then told every employee they need to be on campus like her, all the time, while their children stay home. Always available onsite daycare, bodyguards, for her while others faced the world without them.
I guess my question is, instead of calling the people around an AI CEO their bodyguards and accept their framing, why don’t we call their entourage FUD-care.
One time I was invited to a closed invite only party in San Francisco, with bouncers and security at the door. Once inside I crossed paths with Marissa Mayer and her two, yes two, bodyguards. Inside the perimeter. The musician performing on stage next to us was infinitely more famous, more wealthy, and yet had no personal security.
I’m sure if Marissa Mayer were CEO of OpenAI she would blame the industry that she is in, her role at the top of it, for what makes her so fearful for her safety. She would sound like Sam Altman. Or Elon Musk. The opposite of Craig Newmark. We should be asking whether some people wear their FUD as a badge, hype it up to get the attention, and see the world as an “othering” game. Credible threat intelligence never seems to be part of their story. Because if it were, they would probably be working on, or at least openly talking about, their role in the death of those 10,000 people in June 2026.
Western Europe had its hottest June on record. Intense heatwaves in 2026 broke temperature records, with peaks up to 9°C above average in France and Germany, according to Copernicus data.The Jerk, 1979. “He hates these cans! Stay away from the cans!”
The message set is identical, not merely similar, all around the world. Russian intelligence officers are embedded in countries, hammering one disinformation line:
Democracy has failed, voting changes nothing, your problems are caused by outsiders and elites, only a strongman restores order.
It’s all bullshit. That script ran through Doppelgänger and Storm-1516 against Germany and through the same channels in the US. Watching the Sahel version of it now is helpful because it is further along the sequence. Africa shows us what the operation looks like after Russian full-capture succeeds: the security providers kill more civilians than the threat they were installed to solve, and information operations stop being a tool of acquisition and become an extraction scheme.
In Mali and Burkina Faso, violence against civilians by the militaries (and their Russian partners) since 2023 has resulted in more civilian fatalities than those caused by the jihadists.
Despite this collapsing house of cards, Russia and its junta allies remain on the offensive with their most potent asymmetric tool: information operations. Audaciously, this is not just directed at shoring up domestic support for the Sahelian juntas but is also targeting neighboring democratically oriented governments in Nigeria, Ghana, Senegal, Côte d’Ivoire, and Benin. Social media accounts linked to Russia and the juntas extol the fictional development and stability realized under the military regimes. Any jihadist gains are blamed on Western collusion.
[…]
West Africa, thus, is in the throes of a pivotal race. Will the relentless negative messaging topple another democratic-leaning government before the fallacy of junta success is exposed? Or will the Sahelian military regimes collapse first, shattering any such illusion?
Russia is a shrinking economy with little to offer other states beyond aging, poorly designed weapons and grievance. Yet its legacy Cold War intelligence network makes it the dominant external actor in the Sahel and much of Africa despite providing 1 percent of the continent’s foreign direct investment, limited security assistance, and a political model few societies admit they would ever emulate. Influence is only made possible by their real product being disinformation, a narrative rather than anything material.
And now for some differences. The vehicle in Africa is still the coup. Russia has been caught in the Sahel, and their pivots to Nigeria and other West African states show they may be losing faith in their own disinformation. In Washington it could be argued whether it is a coup or not, while the public perception is still an electoral vehicle. In Berlin the AfD and BSW look more and more like instruments of Moscow than domestic parties. And the CSU’s Dobrindt keeps showing up to announce Moscow’s latest disinformation operations, a counter-messaging role that shows how deep the intelligence penetration runs.
The US State Department just convened delegations from more than sixty governments in its Loy Henderson Conference Room on July 16th for a Ministerial on the Resurgence of Political Terrorism. Secretary of State Marco Rubio hosted. The fourth opening address came from Stephen Miller, White House Deputy Chief of Staff and Homeland Security Advisor.
Since the State Department published his remarks as an official release, they deserve a LOT of scrutiny for what this man is saying out loud. A senior German official sat in the room, which is perhaps the strangest twist of all because they carry a duty to protect against threats to the German democracy. Andreas Kemper already called this out and supplied the analytical apparatus in German (Faschistoide Rede im Beisein des Bundesinnenministeriums, 20 July 2026).
I will extend from his analysis, because the historical weight of Stephen Miller promoting Nazism to Germans, should be called what it actually is. Here’s why:
Miller opened with a legal framework for politics being framed as domestic threat: NSPM-7, the September 2025 presidential memorandum directing every US law enforcement and intelligence agency to “disrupt, identify, defund, debank, arrest, and prosecute” left-wing political terrorists. He then told the assembled governments that in his non-expert, inexperienced, perspective he predicts left-wing terrorism “always becomes a gulag,” defined as “the mass imprisonment of political enemies.” That, of course, is what the Trump administration has been doing, so Miller just classified his boss as a left-wing terrorist. Next he said Antifa “operates in dozens of countries” through shared funding and organization, which is like saying England and France still exist today as countries instead of being under the Third Reich. From there he said intelligence and police agencies worldwide must cooperate “to root out these organizations”, meaning the ones that won WWII. Civil liberties claims, according to Miller’s world view, are “completely pretextual and disingenuous,” a tactic “the left always uses,” and he instructed his audience that appeals to civil liberties “must fall on deaf ears.” His reasoning is that because the domestic terrorist doesn’t abide by “ordered notion of justice” and “is lying” whenever he invokes his rights, then justice against these “enemies of civilization” must be “completely unflinching.” That’s what Hitler said too. But I’m getting ahead of myself.
He makes use of medical imagery in three doses. First, he warns unchecked left-wing violence “can fester as a cancer and ultimately destroy a society” rather than prevent a right-wing capture and destruction of democracy. Second, he says American jurors who acquit defendants in political cases demonstrate “how deeply the cancer has begun to infest your society.” If you’re not thinking this guy is parroting Hitler, you haven’t read Hitler. Third, assassination attempts are called “a fatal cancer to civilization.” After the third dose Miller declared US immigration enforcement attacks on communities are running into “repeat, systemic, organized, funded insurrection, an armed resistance against the federal government.” He slathered this claim with a bizarre and unattributed statistic of an 8,000 percent increase.
Then his speech leaves policy behind altogether and goes into Mein Kampf mode:
The leftist looks at a perfect family with a perfect life and a perfect job and perfect kids that goes to church every Sunday and is filled with a feeling of inadequacy and jealousy, and they covet. And they turn those emotions ultimately into a desire to subjugate, to oppress, and to inflict pain and suffering.
The enemy, as Hitler used to say, is marked on the body.
Not one of the people that is demonstrating looks like a normal person. Not one looks normal. They’re all deformed in some way, in their appearance, in their dress, in their mannerism. […] Every one of them, through the course of their life and their decisions, has scarred their body and their appearance in many different ways, to the point in which their outer appearance becomes a manifestation of their inner hatred.
The remedy Miller tells us to use is instinctual, improvised. “Trust your instincts,” he told assembled government ministers, presumably not realizing their instinct may have been to jump up and slap him in the face. He stated they should know what normal is (not Miller), what beautiful is (not Miller), what good is (not Miller). Seriously, why didn’t anyone at that point say “let me stop you right there, your speech just killed itself”. Instead he droned on about the Bible coveting the “morally superior,” and that ember, he warned, ends where “good families are dragged out into the street and executed.”
And, as anyone familiar with the urgency clause will surely recognize, Miller said those who wait until the threat is undeniable “already lost the battle.”
Kemper breaks this speech down in German using categories German scholarship built for exactly this material, and each sorting operation runs nice and neat.
The cancer metaphor of Miller is the most exhaustively documented figure in National Socialist propaganda language, the subject of a German doctoral dissertation and a centerpiece of Susan Sontag’s Illness as Metaphor, which traced the tumor image through Hitler’s rhetoric. It biologizes society and divides the healthy from the sick. It then licenses excision as therapy. You know, genocide. Miller is promoting that.
The deformity passage of Miller reproduces the degeneration aesthetics George L. Mosse dissected in The Image of Man: the enemy legible on the body, ugliness as the outward sign of inner corruption, a physiognomic doctrine Alfred Rosenberg codified for the NSDAP. Miller at this point may as well have put on his Nazi moustache, hat, throw a salute and snap his heels.
The Miller plea that rights claims “must fall on deaf ears” removes the political opponent from the protection of law by declaring his relationship to law fraudulent in advance. The jury passage extends Miller’s assertion of a disease into the courtroom, a kangaroo court with a guillotine waiting, if you’re familiar with the Volksgerichtshof and Plötzensee, let alone the Nazi rush to behead anti-fascist Sophie Scholl in 1943.
The instinct rhetoric of Miller then replaces the logic of a dialogue with a secretive intuition that usurps what’s normal and healthy. That’s anti-science for a reason. But I’ll say it again, someone should have jumped up and said his speech was abnormal and unhealthy. Intuition. Right?
The targeting he uses is messy, from left-wing terrorism to Antifa to “the left” to “the leftist”. Kemper notes that a responsibility toward the survivors of fascism demands we should care before applying the label, and so he stops at watered-down, overly-passive, fascist-adjacent (faschistoid). The transcript is undeniably fascist, anti-democracy, and full of hate.
As a historian, I argue this is a disgrace to the dead, those who fought against Nazism. As someone who lost so much to those who refused to call Hitler out for what he was, I believe we have a responsibility to take care that we DO NOT fail to stick the label where it fits exactly. It is the lack of labeling, often by the weak center determined to avoid crying wolf, which grants the wolf the power to destroy that herd.
Let me lay it out here, as every journalist should. This table is literally a test against NS primary sources, seven criteria that Miller passes with flying swastikas.
Miller, 16 July 2026
Nazism
Mechanism
Primary source
“can fester as a cancer and ultimately destroy a society”; “a fatal cancer to civilization” (the figure appears three times)
Hitler to Adolf Gemlich, 16 September 1919: the Jew as “racial tuberculosis of the nations,” the remedy a systematic “elimination” leading to “removal”
Disease metaphor converts a political opponent into pathology. Treatment of a pathogen requires excision rather than debate. Susan Sontag traced the figure through Hitler’s rhetoric in Illness as Metaphor (1978); Robert Proctor documented the tumor image in NS medical language in The Nazi War on Cancer (1999).
“repeat, systemic, organized, funded insurrection, an armed resistance against the federal government”; rights appeals “must fall on deaf ears”
Verordnung des Reichspraesidenten zum Schutz von Volk und Staat, 28 February 1933: issued “zur Abwehr kommunistischer staatsgefaehrdender Gewaltakte,” suspending seven basic-rights articles of the Weimar constitution the day after the Reichstag fire
A claimed communist terror emergency becomes the legal instrument that strips civil liberties from everyone the state accuses. Mass arrests of the left followed within days, then extended across the opposition.
“Trust your instincts… You know what normal is. You know what beautiful is. You know what good is.”
Gesetz zur Aenderung des Strafgesetzbuchs, 28 June 1935: the new paragraph 2 punished any act deserving punishment “nach gesundem Volksempfinden,” healthy folk feeling
Intuition of the normal and the healthy replaces the statute as the standard of judgment. The Allied Control Council found the clause so central to NS justice that Proclamation No. 3 of 1945 banned it by name.
“They’re all deformed in some way, in their appearance, in their dress, in their mannerism… their outer appearance becomes a manifestation of their inner hatred”
“Entartete Kunst,” Munich, opened 19 July 1937: confiscated modern art exhibited as sick, degenerate, and alien to the healthy nation
The enemy is marked on the body and in aesthetic form. Ugliness certifies inner corruption. George L. Mosse documented the doctrine in The Image of Man; Rosenberg codified it for the party in the Mythus.
“Antifa… operates in dozens of countries all throughout the world. They share common networks of funding and organization”; the leftist “fundamentally motivated by envy, by hatred, by jealousy”
Goebbels, Nuremberg party congress, September 1935: Bolshevism as “the declaration of war by Jewish-led international subhumans against culture itself”
A world conspiracy of the civilizationally alien, driven by hatred of culture rather than by political conviction, justifies transnational persecution and dissolves the distinction between opponent and enemy.
“If you wait until the point where the worst outcome is so obvious that no one can deny it, you’ve already lost the battle… it’s already too late”; “good families are dragged out into the street and executed”
Goebbels, Sportpalast, 18 February 1943: Bolshevism plotting to plunge Europe into chaos; Germans refuse to “wait like the hypnotized rabbit until the serpent devours them” and instead “recognize the danger in good time and take effective action”
Atrocity prophecy plus preemption logic. The imagined future massacre licenses total measures in the present, and raising the alarm too loudly becomes a virtue by definition.
“the jury has refused to convict for purely political reasons… it demonstrates how deeply the cancer has begun to infest your society”
Hitler, Reichstag address, 26 April 1942: as “supreme Law Lord” he claims the power to remove judges and override “so-called acquired rights” whenever verdicts displease the leadership
Courts that acquit are declared diseased organs of the nation. Judicial independence dissolves into a loyalty test, and the acquittal itself becomes evidence of infestation. The passage was entered at Nuremberg as prosecution exhibit NG-752.
Now the facts, because you should care about them even though Miller doesn’t.
Conclusion slide to my award-winning presentation on Big Data Integrity Breaches, KiwiCon 2016
Europol’s EU Terrorism Situation and Trend Report 2026, published weeks before the ministerial and built from member state submissions, records twelve left-wing and anarchist attacks across the entire European Union in 2025: ten completed in Italy, one in Greece, one failed, every target a building or a vehicle. Casualty count zero. Arrests in the category across all member states came to thirteen, and Germany contributed zero of them. The category has fallen by more than half in two years, from 32 attacks in 2023 to 12 in 2025, while the youngest formal terrorism arrestee in the Union, twelve years old, was linked to the right-wing category.
The German government’s own record doubles-down on this. Germany’s actual 2025 record, presented by Dobrindt and Münch on June 9, is that there were 42,544 right-wing offences and 1,598 right-wing violent crimes, rising over seven percent. All of it enters the Europol terrorism table as a big fat zero because German prosecutors charge right-wing terror tactics such as shelter arson and street violence under ordinary criminal law, almost never under §129a where it belongs. Compare this to Italy where terrorism is applied to property destruction to create the appearance of a “left wing terror wave”. In other words, on an equal definition the Europol terrorism table would show right-wing terrorism miles above left-wing. The statistics lie, always, but it’s not like we can’t see the direction here.
The Bundesinnenministerium itself maintains that the greatest extremist threat to German security comes from the right. In April it answered a parliamentary question by describing an “Antifa Ost,” the network Washington designated a Foreign Terrorist Organization in November 2025, as largely dismantled. A non entity that the Americans are trying to spin up with nothing behind it. Total membership was estimated by the Bundesamt für Verfassungsschutz in the low double digits. Miller’s empty-hat argument about the jury threat also doesn’t have legs. The 41 percent conviction rate in EU left-wing proceedings comes from Eurojust data covering jurisdictions that put terrorism cases before professional judges instead of juries, so the ideologically captured juror of Miller’s story doesn’t exist in any of these courtrooms: courts convict when evidence exists.
I also should mention that Miller’s actual experience and expertise is lacking. All he brings to the table is a lot of anger and a bachelor’s degree in political science from Duke, class of 2007. His formal record ends there, which perhaps explains why his presentations are so propagandist and devoid of facts like these.
Miller’s career speaks for itself: communications aide on Capitol Hill, press secretary to Senator Jefferson Beauregard Sessions III (third generation Civil War lost cause), campaign speechwriter, then White House advisor with an immigration portfolio and, between administrations, a litigation advocacy group. That’s a specific type of loyalty to a losing side in history, which exposes him against the prior staff of the office he now occupies.
Frances Townsend was a career federal prosecutor; John Brennan spent 25 years in the CIA; Lisa Monaco led the Justice Department’s National Security Division; and Tom Bossert was a homeland security and cyber specialist. Miller is the first Homeland Security Advisor whose qualification consists entirely of gobbling like a Goebbels. The strangest part, perhaps, is that he is running the playbook of the side that lost WWII as if it will turn out different this time.
Miller isn’t actually coming at this unprepared, as much as he doesn’t seem to have the background for it. Across two decades he has carried a particular form of purity slogan. Miller’s senior yearbook page at Santa Monica High School, class of 2003, carries a single quotation, from Theodore Roosevelt:
There can be no fifty-fifty Americanism in this country. There is room here for only 100 percent Americanism, only for those who are Americans and nothing else.
Miller was overtly spreading a known white nationalist slogan as his ticket into American politics, focusing on communications.
Set the KKK wizard beside Miller’s instruction that nations must trust instincts because normal is known, and the purity test is clearly the same, just swapping out a word. Roosevelt’s line was already the loyalty-purity doctrine of the wartime crusade, and John Higham’s standard history of American nativism, Strangers in the Land, traced “one hundred per cent Americanism” from that crusade directly into the tribalism of the Klan decade. This is settled history, into which Miller saddled up and grabbed a robe.
By 2003 the phrase carried the Klan’s brand in historical memory, which is why historians reach for it as a title when they mean the hooded movement. While the naive reader sees patriotism with Teddy’s name attached to a sentence, it is the readers who know the KKK who hear the loud whistle. Miller’s record further documents this habit, because it was no accident. The leaked Breitbart correspondence shows him invoking Calvin Coolidge, whom Hatewatch notes is lionized by white nationalists for his remarks condemning race mixing, alongside the immigration regime of 1924, the restriction law the Klan pressured Congress to pass. His method is to paper presidential names on the white supremacist creed so that it still gets through.
In November 2019 the Southern Poverty Law Center published its analysis of more than 900 emails Miller sent to Breitbart editors in 2015 and 2016, while he served as an aide to Senator Sessions and then as a Trump campaign advisor. The correspondence shows him recommending Jean Raspail’s The Camp of the Saints, the replacement-fantasy novel of the white nationalist canon, and circulating material from VDARE and American Renaissance; more than 80 percent of the reviewed emails related to race or immigration. The SPLC maintains an extremist-file entry as a result.
Miller was known in high school for his extremist views, as evidenced in his purity slogan in a 2003 yearbook. He then was known for his white nationalist reading list of a Senate aide in 2015, which brings us back to the recognition doctrine delivered as counterterrorism policy in 2026. The Washington speech this week is the same Miller he has always been.
Germany received an invitation at ministerial level to listen to a Nazi. They accepted, willingly. Alexander Dobrindt sent a department head, the Abteilungsleiter für Öffentliche Sicherheit of the Bundesinnenministerium, a role whose professional formation includes the recognition of extremist rhetoric. Berlin featured in the sales pitch from “man of many hats all saying loyalty” Rubio, who told the delegates they were in the room “because the lights went out in Berlin for five days this winter,” a reference to the January blackout claimed in a letter attributed to a Vulkangruppe.
It’s weird as a reference because, as an exhibit, it comes long after the data on the table that ends in December 2025. And let me be clear about that group. It’s a Russian sabotage operation wearing a false-flag costume, run on the disposable-agent template that Germany’s own four federal security agencies published in September 2025, as I documented when the claim letter failed every left-wing naming test.
I’ll say it again, the joint BfV, BND, BKA, und BAMAD campaign in late 2025 described Russian services commissioning Wegwerf-Agenten through social media for arson against energy, transport, and rail, which are the exact target class, recruitment channel, and conviction-free outcomes that the Vulkangruppe record shows across fifteen years.
Anyone calling Vulkangruppe left-wing is selling you a fat lie.
During the meeting the German delegation agreed that the follow-up event, a workshop of experts, will take place in Germany. A ministry spokesman confirmed the agreement to Der Spiegel and explained the choice of venue with logistics.
In a proper functioning Germany, when Stephen Miller steps into Germany he will be arrested on charges of being a present threat to democracy.
The Federal Republic spent eight decades building the professional capacity to recognize the vocabulary he uses, and its interior ministry trains senior officials in it. One of them sat through the claims about a gulag, the claims about a cancer, the claims about deformed bodies, the claims about an instinct of the healthy, and the claims about executed families, all delivered from a government podium as counterterrorism doctrine. Germany assesses the threat Miller claims as few to low double digits. Whereas Miller himself exhibits all the flags of a right-wing extremist. Everything required for recognition was present in the room. The ministry booked the venue and enabled him.