U.S. District Judge Trina Thompson in San Francisco ruled on Monday that owners could try to prove that Tesla coerced them into paying high prices and suffering long waits to have their vehicles fixed, under fear of losing warranty coverage.
Owners said Tesla’s alleged coercion violated the federal Sherman antitrust law and California antitrust law.
Thompson found evidence of a repairs monopoly in Tesla’s alleged refusal to open enough authorized service centers, and its designing vehicles to require diagnostic and software updates that only the company could provide.
Tesla presumably thought they were above the law, as they intentionally setup a service model to flagrantly violate the customer right to repair.
A little history for those who don’t remember twenty years ago the “bullshit” way of doing business ended badly.
Ken Rice, at the time the CEO of Enron Broadband Services, smiled. “He leaned back, popped his cowboy boots up on his desk, and proceeded to feed me the biggest line of bullshit ever,” Moss told us, two decades later. “And I bought every bit of it.”
Within a year, the company would collapse, Enron Broadband would be sold for scrap, and Ken Rice would be fighting to stay out of prison. Six years later, he would lose that fight.
With no chips and now no talent, what else can the Tesla fraud be but another fraud?
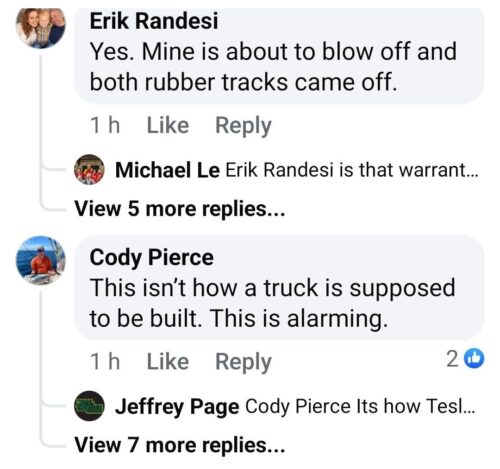
We already know the “go anywhere truck” can’t handle any moisture at all. Now reports are flying in that it can’t handle pressure either, as contact with anything tears it apart.
So today, I got a little too close to the fence and boy did it mess up the truck. We’re not talking about running into the fence directly but trying to back up and then I got a little too close and then one of the panels got caught in the post and it really messed up the post but it bent as well. Check out the pictures.
Bear in mind that this is parking speeds, very low speed. Judging from the post, that’s some serious damage so if this were a person, they’d be pretty messed up.
If this were a person…
They might already have been killed by large razor sharp metal panels flying off at highway speeds like a helicopter that loses its blades.
Fast or slow the Tesla design fails basic pressure tests, and creates a dangerous hazard on the road.
Pennsylvania local news WGAL says a Tesla came into contact with another car during a change of lane at high speed, sending the other car into opposing traffic head-on. An oncoming cement truck impacted so hard it completely destroyed that car, instantly killing that driver before itself rolled off the road.
a blog about the poetry of information security, since 1995